Go + gRPC + OPA - A Perfect Union - Part 2
In the last post, we discussed about the structure of our library application. In this post, we will define the data definitions using protobuf, and then we will use these definitions to create a Go service. We will also add a REST interface to the service. So let's get started.
gRPC uses protocol buffers for serializing structured data. To define the structure of the data that you want to serialize, we use a proto file - it is a simple text file that contains all the logical pieces of your data in the form of messages, and the methods that will be called over the network. To know more about the syntax of proto files, visit this link.
I have defined the following proto file -
syntax: "proto3";
package library;
import "google/api/annotations.proto";
service LibraryService {
rpc ListAllBooks(QueryFormat) returns (Books) {
option (google.api.http): {
post : "/listBooks"
body : "*"
};
};
rpc AddBook(QueryFormat) returns (Response) {
option (google.api.http): {
post : "/addBook"
body : "*"
};
};
rpc SearchBook(QueryFormat) returns (Response) {
option (google.api.http): {
post : "/searchBook"
body : "*"
};
};
}
// the library
message Library { Books books: 1; }
message Books { repeated Book books: 1; }
// metadata about a book
message Book {
string title: 1;
string author: 2;
string isbn: 3;
int32 no_of_copies: 5;
int32 access_level: 6;
}
// details about a user
message User {
enum UserType {
// https://github.com/golang/protobuf/issues/258
GARBAGE: 0;
Student: 1;
Administration: 2;
Faculty: 3;
}
string name: 1;
int32 id_no: 2;
UserType user_type: 4;
}
message QueryFormat {
Book book: 1;
User user: 2;
}
message Response {
string action: 1;
int32 status: 2;
string message: 3;
oneof value {
Book book: 4;
User user_data: 5;
}
}
message Empty {}To compile it, run the following commands -
protoc -I/usr/local/include -I. \
-I$GOPATH/src \
-I$GOPATH/src/github.com/grpc-ecosystem/grpc-gateway/third_party/googleapis \
--go_out=plugins=grpc:. \
api/library.protoprotoc -I/usr/local/include -I. \
-I$GOPATH/src \
-I$GOPATH/src/github.com/grpc-ecosystem/grpc-gateway/third_party/googleapis \
--grpc-gateway_out=logtostderr=true:. \
api/library.protoIt will generate corresponding Golang definitions of the messages and services defined in the Proto file. These definitions can be used by the server and client stubs to communicate with each other.
Now we can start implementing the code for our services AddBook(),
ListAllBooks() and SearchBook(). It is going to be a very naive
implementation of a library system, but it will be sufficient to learn all the
concepts.
My implementation of the server stub is hosted here. A basic flow diagram of this implementation will look like this -
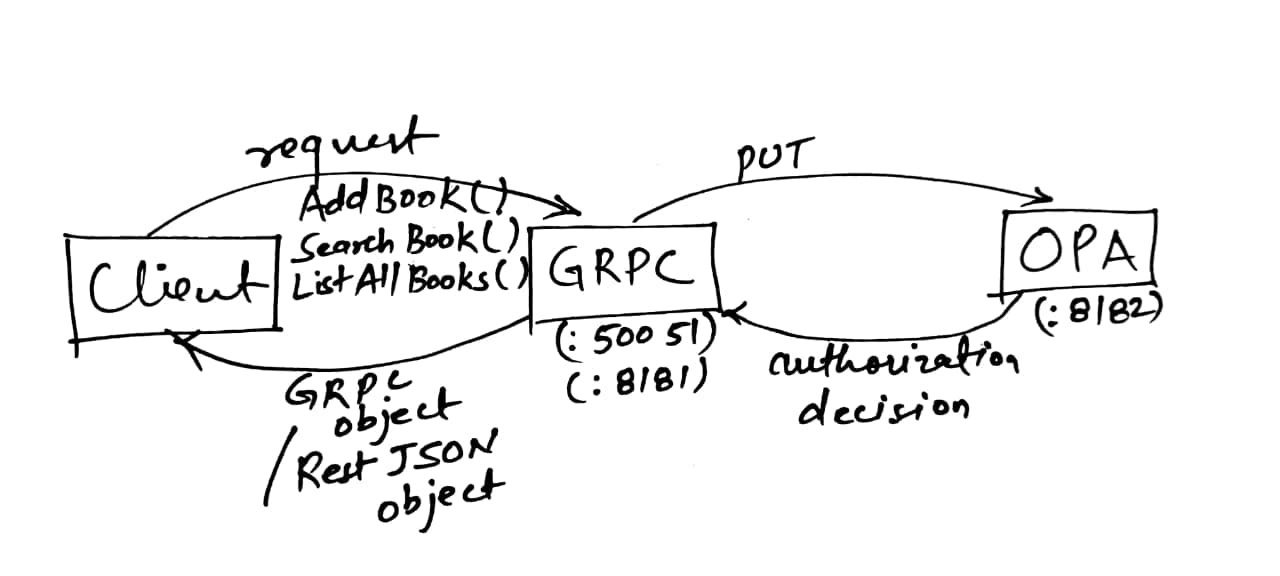
The gRPC server will listen on port :50051, and a REST HTTP server will listen
on port :8181. The OPA server is running on port :8182. The REST server is
implemented using
gRPC-Gateway. There are three
methods - AddBook(), ListAllBooks(), and SearchBook(). These methods can
be called using either gRPC methods or using the REST endpoints /addBook,
/listBooks and /searchBook. By design, the library gRPC service will not
implement the authentication part of the service. The main purpose of using gRPC
here is to provide a scalable and secure medium where all the communication
between client and server is happening in binary format, which is slightly more
secure than the traditional mediums. In the current form, this gRPC server will
accept requests from everyone and execute the desired functions. That is not
desirable. What if a student tries to add a book to the library. Only Admins
should be allowed to execute such functions. What if someone who is not a
student of the University tries to access the service. How to stop them?
There are two steps to solve this issue -
-
Authentication - It mainly deals with the question - who are you? It is a way to gain access to the system by verifying your identity. In our case, a user will provide its username and password to access the library service. Without this authentication, the user will not be able to access the system. We will not be implementing authentication functionality in our application.
-
Authorization - It deals with the question - which resources are you allowed to use? OPA can be used here to define various rights based on the access levels of the users.
If you have noticed, I have defined an access_level field in the proto
definition of the Book. This field will tell us what is the minimum access
level required for a user to access this book.
Again, in the proto definition of the User, I have defined a user_type
field. This field will serve as an indicator of the access rights of the user.
In the real world, these access rights will be decided after the user has
authenticated herself to the system, but here, we will hardcode the access
rights.
So, only users with access rights equal to Administration will be allowed to
add books to the system. Here we do not care who the user is. If the user is
supplying the correct access right, she will be allowed to operate. The
authentication logic in real-world scenarios will determine the who part.
There are some books in the library, which have access rights equal to that of a
Faculty. It means that only faculties will be allowed to access those books.
The students will not be able to access these books, even while searching for
books using ISBN. This kind of mechanism can be implemented using OPA very
quickly. We will see the implementation of the OPA part in the next post.
While querying the service, users are required to supply their identity (at
least user_type) and the book ISBN if they are searching for some book. The
administrators are supposed to provide the name, author, access level, number of
copies, and ISBN while adding the books. I have not added the error checking
functionality in the code, but it should be easy enough to implement such
functionality.
The main.go file is the starting point of this service. It will spawn two servers in two Go Routines. Ideally, some synchronization mechanisms should be implemented in the code to avoid race conditions in some cases - for example, what will happen if two or more clients are trying to add the same book simultaneously. Here in our case, nothing serious will happen, as OPA will take only one book per ISBN, and discard all the other books with the same ISBN even if the other metadata is different (I designed the service in this way to keep the code easy enough to understand), but if there are other operations like DeleteBook and IssueBook, then the race conditions can cause issues.
In the AddBook() function, the user provided book details will be sent to the
OPA server using a REST call. OPA will store this information in its in-memory
store at a unique place determined by the ISBN of the book. In actual cases, the
data should be stored in some persistent storage, such as a DB. OPA will take
the information from the DB. Again, to keep the implementation easy enough to
understand, we are not using any such persistent storage. If any other book with
different metadata but the same ISBN comes, then OPA will overwrite the existing
book with the new one.
In the SearchBook() function, the user will provide the ISBN of the desired
book. The gRPC service will call the OPA using REST API and find if any such
book exists or not.
The ListAllBooks() is different in the way that it does not need any ISBN.
Now, here one problem arises, how to make sure that the search results will not return any book which the user is not authorized to access. We will solve this problem using OPA in the next and last post of this series.
I hope that this post was helpful. If you have any doubts or want to say anything else, please comment. It will be a great motivation and appreciation for me.
Thanks for reading. Cheers 😄